학습목표
데이터 분석 업무에서 머신러닝 모델링이나 시각화를 위해
raw data 적절한 형태로 변환해야 한다.
즉, 데이터 변환, 필터링, 전처리 작업이 필요하다.
예컨대, NA나 결측값을 다른 방식으로 변경하는 등의 작업을 일컫는다.
이런 작업을 위해 데이터 처리에 특화된 Package들이 있다.
오늘은 특화 패키지 중 대표적인 2개와, 기본함수를 학습해 볼 것이다.
- plyr (플라이알)
- Pliers(집게형 공구) + r 이란 의미 = r을 사용하는 도구 -> 패키지 구현 언어 R
- R의 단점은 complier기반의 다른 언어에 비해 속도가 느린 단점이 있는데 이 것이 그대로 반영됨
- dplyr(디플라이알)
- data frame + Pliers + R : C++을 기준으로 만들어져 dataframe을 r 로 분석하는 도구. 속도 빠름
- vector나 data frame에 적용할 수 있는 기본 함수
실습할 데이터
iris(아이리스)
iris란? ▼열기
iris란?
붓꽃의 종류와 크기에 대해 측정한 데이터로 통계학자 피셔라는 사람이 측정해 제공했다.
워낙 대표적인 자료라 R에 내장 되어 있다.
<컬럼 : 5가지 >
Species: 3가지
Sepal.Length : 꽃받침의 길이
Sepal.width : 꽃받침의 너비
Petal.width : 꽃잎 너비
Petal. Length : 꽃잎 길이
기본함수
- head()
- 데이터셋의 앞에서 부터 6개 데이터를 추출해준다

- 데이터셋의 앞에서 부터 6개 데이터를 추출해준다
- tail()
- 데이터 셋의 뒤에서부터 데이터를 추출한다. 디폴트값은 6개. 데이터프레임 외에도 적용 가능하다.
- tail(iris,n=3)
- View()
- 4. dim():
- data frame에 적용할 때 행과 열의 개수를 알려줌
- 선형자료구조(VECTOR, LIST)에서는 사용할 수 없다
- dim(iris) # 150 5
dim(var1) # null
- dim(iris) # 150 5
- nrow()
- 행의 개수 구하기
- ncol()
- 열의 개수
- str()
- str(iris)
- data frame에 대한 일반적인 정보를 추출
- summary() :
- data frame의 요약통계량
- Min, Max, 사분위, 평균(mean), 중간 값(Median)
- ls()
- data frame의 column명을 vector로 추출
- 오름차순으로 자동 정렬하여 생성
- rev()
- 선형자료구조 데이터를 역순으로 정렬
- length()
- 주의사항
- 선형자료구조: 길이를 도출
- data Frame : 컬럼의 개수
- Matrix : 원소의 개수
- 주의사항
var1 <- c(1,2,3,4,5,6,6,7)
Plyr package
-
데이터 결합
- key값을 이용해 두 개의 data frame을 병합
- 세로방향 병합 (열방향 결합)
- 주의사항: R에서는 LeftJoin이 default 이다. 다른 언어에서는 Inner Join이 기본
- Key 1개를 이용한 결합
x = data.frame(id = c(1,2,3,4,5),
hight = c(150,190,170,188,167))
y = data.frame(id = c(1,2,3,6),
weight = c(50,100,80,78))
join(x,y,by="id", type="inner") # join(결합변수1,변수2,type="",by="키")
join(x,y,by="id", type="left") # default
join(x,y,by="id", type="right")
join(x,y,by="id", type="full")
- Key 2개를 이용한 결합
x = data.frame(id = c(1,2,3,4,5),
gender = c("M","F","M","F","M"),
hight = c(150,190,170,188,167))
y = data.frame(id = c(1,2,3,6),
gender =c("F","F","M","M"),
weight = c(50,100,80,78))
join(x,y,by=c("id","gender"), type="inner") # join(결합변수1,변수2,type="",by="키")
join(x,y,by=c("id","gender"), type="left") # default
join(x,y,by=c("id","gender"), type="right")
join(x,y,by=c("id","gender"), type="full")
- plyr은 dplyr보다 속도가 느려 요즘은 거의 사용되지 않는다.
- Join 형식도, Dplyr은 결합 종류에 따라 다른 함수로 구분해 놓고 있다.
2. 범주형 변수를 이용해 그룹별 통계량 구하기
- 범주의 종류를 알아내기
- str과 unique 두 종류가 있다. str은 모든 열을 나열해 주기 때문에, 적은 열의 데이터에서 유용하지만, 대량데이터에서는 복잡한 결과를 보여준다. 대량 데이터에서는 unique 함수를 대신 이용해 범주 종류를 찾아낼 수 있다.
- str()
- unique()
- 중복제거 후 남은 것 알려주기
- # 특정 변수의 값 목록을 알 고 싶을 때 사용하기 좋음


- iris의 종별 꽃잎 길이의 평균과 최대값을 구하라
- tapply() : 함수를 적용하는 함수
- 특징: 한 번에 한 개의 통계치만 구할 수 있다!
- tapply(대상 column,기준,적용함수) == (꽃잎 길이, iris범주형변수 column, mean)
- ddply() : tapply와 같은 역할을 하는 함수
- 특징: 한 번에 여러개의 통계치를 구할 수 있다
- tapply() : 함수를 적용하는 함수
tapply(iris$Petal.Length,
iris$Species,
FUN = mean)
tapply(iris$Petal.Length,
iris$Species,
FUN = max)
df<- ddply(iris, # 데이터
.(Species), # 기준변수 (범주형)
summarise, # 요약통계
avg = mean(Petal.Length), # 산출값1
sd = sd(Petal.Length)) # 산출값2
class(df) # 데이터 프레임으로 떨어짐
View(df)
plyr에서는 join()과 통계값을 구하는 함수 정도를 알아두면 좋다.
실제로 data frame을 핸들링 할 때는 plyr 을 개량한 dplyr을 이용한다
Dplyr
dplyr 사용 이유
(1) C++로 구현되었기 떄문에 속도가 빠르고
(2) 코딩시 chaining을 사용할 수 있다
Chaining이란?
일반적으로연속 프로그래밍을 위해서는 다음과 같이 변수를 생성하는데
var1 <- c(1,2,3,4,5)
var2 <- var1 *2
chaining에서는 변수의 생성 없이 한 줄로 만들어 낼 수 있다
틀린 문법이지만, 예컨대 아래와 같은 개념이다.
var1 <- c(1,2,3,4,5) >> *2 >> +5
새로운 데이터 활용
이용건수 및 이용금액
- 공유폴더에서 다운로드
install.packages("xlsx")
library(xlsx)
excel <- read.xlsx(file.choose(),
sheetIndex = 1,
encoding = "UTF-8")
excel
str(excel)
ls(excel)
tbl_df(excel)
dplyr의 주요함수
- table_df() : 현재 console 크기에 맞추어서 data frame을 추출하는 함수
제공된 excel을 읽어보니 data frame을 생성한 후 column명을 보니 변수명이 지저분
Amt17 : 2017년도 이용금액
Y17_CNT : 2017년도 이용횟수
통일해 주자
2. rename
- 기본문법 : rename(data frame, 바꿀 컬럼명1 = 이전컬럼명1, 바꿀 컬럼명2 = 이전컬럼명2,....)
- 주의사항 : column명을 수정한 새로운 data frame이 return된다. 기존 데이터 프레임이 변경 되는 것이 아님에 유의
df <- rename(excel,
CNT17 = Y17_CNT,
CNT16 = Y16_CNT)
tbl_df(df)
3. 하나의 data frame에서 하나 이상의 조건을 이용해서 데이터를 추출하려면 ?
- filter(data frame, 조건1, 조건2,...)
# 성별이 남자인 사람만 추출
filter(excel, SEX == "M")
# 성별이 남자이면서 서울 거주자만 추출
filter(excel,
SEX == "M",
AREA =="서울")
filter(excel,
SEX == "M" & AREA =="서울") # 하나의 조건으로 인식
# 모든 사람들 중에 지역이 서울 혹은 경기인 남성들 중 40살 이상의 사람들의 정보 추출
filter(excel,
AREA =="서울" | AREA == "경기",
AGE >= 40,
SEX == "M")
# 모든 사람들 중에 지역이 서울 혹은 경기 혹은 제주인 남성들 중 40살 이상의 사람들의 정보 추출
# 가독성 높은 표기법
filter(excel,
AREA %in% c("서울", "경기","제주"),
AGE >= 40,
SEX == "M")
4. arrange
- 문법: arrange(data frame, column1, column2,...)
- 주의: 정렬 default는 오름차순
- 내림차순으로 정렬하려면 desc()옵션 포함
df<-filter (excel,
AREA =="서울",
SEX =="M",
AMT17>=400000)
arrange(df,desc(AGE))
# 5.Select(column1, column2...)
# 추출하길 원하는 column을 지정해서 해당
# Column만 추출할 수 있다
# filter는 레코드 선택, selects는 컬럼을 선택
# 서울살고 남자, 2017년 처리금액이 400,000원
# 이상인 사람을 나이가 많은 순으로
# ID와 나이, 그리고 2017년도 처리 건수만 출력
df1<- filter(excel,
AREA =="서울",
SEX =="M",
AMT17>=400000) %>%
arrange(desc(AGE)) %>%
select("ID", "AGE", "Y17_CNT")
# select로 연속된 열을 뽑을 때
df1<- filter(excel,
AREA =="서울",
SEX =="M",
AMT17>=400000) %>%
arrange(desc(AGE)) %>%
select(ID:AGE) # 또는"ID" : "AGE
# 특정 열을 제외하고 뽑을 때
df1<- filter(excel,
AREA =="서울",
SEX =="M",
AMT17>=400000) %>%
arrange(desc(AGE)) %>%
select(-SEX) # 또는 -"SEX"
df
6. 새로운 Column을 생성하기
- R기본 기능으로 만들기
데이터프레임이름$생성열이름만들려는 column의 이름을 $뒤에 작성해 준다
구매금액이 50만원이 넘는 사람을 정해 VIP로 지정해 excel이라는 데이터 프레임에 grade라는 열을 생성해보자
excel$grade <- ifelse(excel$AMT17>=500000,
"VIP",
"NORMAL")
View(excel)
- dplyr 의 함수 사용 하기 : mutate(data frame, 컬럼명1 = 수식1 또는 값, 컬럼명2= 수식2)
- 경기사는 여자를 기준으로 2017년도 처리금액을 이용하여
처리금액의 10%를 가산한 값으로
새로운 컬럼 AMT17_Real을 만들고
AMT17_Real이 45만원 이상인 경우
VIP컬럼을 만들어서 TRUE, 그렇지 않으면 FALSE를 입력하라 - 함수 내에서 값 ASSIGN을 할 때는 <-를 사용할 수 없다 . = 만 제대로 작동
- chaning을 통해 변수를 생성하고 생성한 변수를 바로 활용 하려 할 때, R기본 방식($)은 R이 구문의 요청사항을 제대로 인식하지 못하는 경우가 많다. 따라서 mutate를 반드시 사용해야 한다
- 경기사는 여자를 기준으로 2017년도 처리금액을 이용하여
df <- mutate(excel,
AMT17_real = AMT17*1.1) %>%
mutate(vip = ifelse(AMT17_real>=450000,
"TRUE",
"FALSE"))
또는
df <- filter(excel, AREA=="경기" & SEX=="F") %>%
mutate(AMT17_REAL = AMT17*1.1,
VIP = ifelse(AMT17_REAL >= 4500,
TRUE,FALSE))
7. group_by() & summarise()
그룹별로 자료를 묶어서, 요약제시 할 때 사용
df <- filter(excel,
AREA=="서울" & AGE>30) %>%
group_by(SEX) %>%
summarise( #그룹별 통계를 넘긴다
sum= sum(AMT17), #sum이란 컬럼을 만들어서 AMT17의 합을 넣고 ,
cnt=n()) #cnt라는 변수를 만들어 빈도수를 넣어라
8. join함수가 각 기능별로 독립적인 함수로 제공된다
left_join()
right_join()
inner_join()
full_join()
9. bind_rows(df1,df1)
주의할 점은 컬럼명이 같아야 생각하는 것처럼 data frame이 결합한다
- 컬럼명이 같을 때
df1 <- data.frame(x=c("a","b","c"))
df1
df2 <- data.frame(x=c("d","e","f"))
df2
df3 <- bind_rows(df1,df2)
df3
- 컬럼명이 다를 때
df1 <- data.frame(x=c("a","b","c"))
df1
df2 <- data.frame(y=c("d","e","f"))
df2
df3 <- bind_rows(df1,df2)
df3

연습문제
MovieLens Data Set을 이용해서 처리해보자
- 미네소타 데이터 연구소에서 영화에 대한 평점 정보를 기록해 놓은 데이터
- 평점은 1~5점(5점이 최대)
- 사람이 한 두명이 아님
- 영화의 종류도 굉장히 많다
- Time stamp 개념
0. 데이터를 받았으면 데이터의 구조 확인 / 컬럼의 의미 파악
1. 사용자가 평가한 모든 영화의 전체 평균 평점
mean(rating)
2. 각 사용자별 평균 평점
3. 각 영화별 평균 평점
4. 평균 평점이 가장 높은 영화의 제목을 내림차순으로 정렬해서 출력
(동률이 있는 경우 모두 출력)
5. comedy 영화 중 가장 평점이 낮은 영화의 제목을 오름차순으로 출력
(동률이 있는 경우 모두 출력)
6. 2015년에 평가된 모든 로맨스 영화의 평균 평점
[참고하기]
결합의 종류

- inner join
- key값이 동일한 것만 추출

- Outer Join
- Left Join
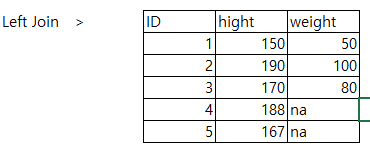
- Right Join
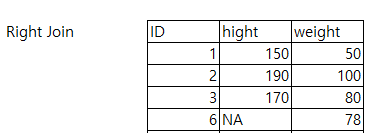
- full Join

TimeStamp란? (Movielens data 변수)
1970년 1월 1일 0시 0분 1초를 1로 기준하여
1초당 1씩 증가하도록 설정한 숫자로 날짜를 나타냄
'데이터사이언스' 카테고리의 다른 글
| 191104 [데이터조작] (0) | 2019.11.04 |
|---|---|
| 3주차 학습 계획 (0) | 2019.11.04 |
| 학습 개요 (10월 11월) (0) | 2019.10.31 |
| 191031 [데이터구축] Kakao Open API 추출/ Selenium 자동 추출 (0) | 2019.10.31 |
| 191030 [데이터구축] R을 이용한 Web Crawling (0) | 2019.10.30 |

